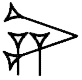

Values: ia4, na4
| ETCSLdisplay | | Sign name: NI.UD (NA4) Values: ia4, na4 |
Encoding and text conventions
EncodingThe default character encoding for the second edition of the ETCSL is Unicode. If your browser cannot display Unicode characters, choose the non-Unicode (Ascii) version of the catalogues and when searching. Unicode is supported by all recent versions of the most popular web browsers. The default Unicode font is Arial Unicode MS. Transliteration conventionsDiacritics which are sometimes transcribed as acute and grave accents over the vowel (á, é, í, ú and à, è, ì, ù) to show a value of a sign are here marked with subscript 2 and 3 respectively. So you will find zu2 not zú and dug3 not dùg. When display is set to Ascii (non-Unicode), the following conventions are used to mark non-ASCII characters in transliterations of Sumerian: In non-Sumerian contexts, e.g. in the translations and in English titles and notes, a set of character entities have been used to render non-Roman Sumerian and Akkadian letters. The most frequent entities are &c; for shin, &g; for nasal g, and &h; for h with breve below. In Akkadian glosses, any diacritic will disappear in non-Unicode view, i.e. long a (ā) will become a, sadhe (ṣ) will become s, etc. Line numbers are shown at the beginning of each line of composite text. Where a composition is extant in discontiguous segments, those segments are lettered, and the line numbering starts again at 1. Line numbers also appear at the beginning of every paragraph of English prose translation, marking the corresponding lines of composite text. For instance, 37-45 would mark the start of the paragraph which translates lines 37 to 45 of the composite text. Line markers also serve as links between the corresponding parts of the composite text and translation. Translation conventionsAll translations are in continuous English prose, in complete sentences as far as possible. The translations are divided into paragraphs for ease of reading. Damaged, missing or untranslatable passages from one to several words in length are indicated by the mark ...... (i.e. two ellipses). Damaged, missing or untranslatable whole lines or passages are indicated as follows: Individual words of which the translation is uncertain are followed by the mark (?). Sumerian words and names are systematically normalised in translation (e.g. Inana, Meš-Ane-pada). Critical apparatus and display conventions
|
 |
© Copyright 2003, 2004, 2005, 2006 The ETCSL project, Faculty of Oriental Studies, University of Oxford |
 |