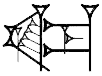
Values: eme
| ETCSLtechnical | | Sign name: KA×ME (EME) Values: eme |
|
The Electronic Text Corpus of Sumerian Literature is encoded using the extensible markup language (XML) in accordance with the Text Encoding Initiative (TEI) guidelines. A number of XML validators have been run on the corpus to ensure its compatibility with XML and TEI. A detailed discussion of the coding practices can be found in the ETCSL manual. To deliver the corpus on the web several technologies and software packages have been used. The most important ones are MySQL (the world's most popular open source database, according to their website), Perl (a stable, cross-platform programming language), PHP (a widely-used, general-purpose scripting language that is especially suited for web development) and the Apache web server software. All these software packages are free for non-profit, academic purposes, and they run on all major platforms. Java scripts and cascading style sheets (CSS) have been used extensively to support the layout of the various pages and views of the corpus. To cope satisfactorily with Sumerian and Akkadian transliterations, Unicode character encoding has been used where needed. Except for one character that is not in Unicode, and hence cannot be displayed properly without using combining diacritics, most web browsers should be able to display our pages provided one uses a recent version of one of the most popular browsers, e.g. Mozilla Firefox, Internet Explorer, Netscape or Opera. More in-depth descriptions of various aspects of coding can be found in the following documents:
The Transliteration principles and the Hyphenation principles, which were written by Jeremy Black in 2004, should be seen as broad outlines. The actual implementation of them may have changed over time. |
| TEI |  |
 |
 |
 |
 |
 |
© Copyright 2003, 2004, 2005, 2006 The ETCSL project, Faculty of Oriental Studies, University of Oxford |
 |