
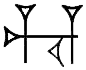
Values: us, uz
| ETCSLuse | | Sign name: ŠE.ḪU (UZ) Values: us, uz |
Exploring the corpusWhen developing the ETCSL into an electronic web resource, we have tried to accommodate the beginner student as well as the more experienced researcher of Sumerian language and literature. All the Sumerian texts, except for the catalogue files, have parallel English prose translations. What's more, every Sumerian word in the corpus has been given an English label or gloss. This gives us the possibility of showing a word-by-word translation of each line of transliterated Sumerian together with the translation (interpretation) of that line in plain English. In the process of attaching a label to every Sumerian word, we have also separated the base of the word from any grammatical morpheme(s) and given it a standardised form. This standardised form is referred to as the lemma, and corresponds to a headword as found in dictionaries. Below is an example of how this information is displayed at the website when choosing the Gloss display (see Searching under Using ETCSL) starting from Advanced search. The first row of the table contains a line of transliterated Sumerian; the next row shows the base forms or lemmas of each transliterated word (here na has been interpreted as a variant form of the lemma na4 and kun as a variant form of the lemma kun4); and the last row shows the English labels or glosses. The following single-cell table contains the English prose translation of the transliterated Sumerian.
It has proved difficult to give a good, coherent line-by-line translation of the original Sumerian. The translations are therefore organised into "paragraphs", where a paragraph can correspond to several lines of transliterated Sumerian. This makes it difficult sometimes to match a specific line of Sumerian to the corresponding translation. Line c561.151
To aid in the matching of original and translation, a paragraph-aligned layout can be displayed by clicking on the line numbers corresponding to the translation paragraph (in blue above). Note that we still do not get a line-by-line or line-to-sentence translation. However, this display should make it easier to see which lines in the transliteration correspond to which parts of the English paragraph. Paragraph t561.p49 (line(s) 146-152) Click line no. for paragraph-aligned layout of transliteration and translation.
The Browsing and Searching pages contain more details about how to manipulate and display the corpus data, e.g. how to display the data as shown above. A more technical introduction to the transliteration and coding of the Sumerian data can be found under Technical info on the home page. Generating listsThe ETCSL consists of nearly 400 compositions of transliterated Sumerian with parallel English prose translations. Both the transliterations and the translations can be browsed (read online), searched, and printed from the website. Apart from the corpus itself, the website also contains ways of generating lists from it. The most useful ones are the "Glossary", the "Emesal glossary", and the "List of proper nouns". The first of these is a complete list of all the lexemes attested in the corpus apart from numbers and proper nouns. The Emesal glossary identifies all Emesal words in the corpus, while the proper nouns list contains all the recognised names in the corpus. In addition to these lists, which are automatically generated from the corpus on the fly, the website includes other lists and information intended to help the user in exploring Sumerian literature and language, e.g. a list of cuneiform signs and transliteration values. |
 |
© Copyright 2003, 2004, 2005, 2006 The ETCSL project, Faculty of Oriental Studies, University of Oxford |
 |