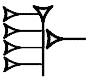
Values: kindagal2
| ETCSLcuneiform | | Sign name: GAL.URI Values: kindagal2 |
Cuneiform writingIntroductionCuneiform writing was most probably invented in Uruk in southern Mesopotamia (modern Iraq) about 3400 - 3300 BCE (Glassner 2003:45). It was invented to keep records of goods and services, and the language that was recorded was, as far as we can tell, Sumerian. The cuneiform script was later adopted by other people speaking languages as different as Akkadian, a Semitic language, and Hittite, an Indo-European language. Sumerian itself is, as far as we know, not related to any other living language. It is a language isolate. In its early stages, cuneiform writing was bascially logographic in nature, and a sign represented a content word (a thing or an action). The drawback of a purely logographic writing system is of course that the number of signs needed to represent all the words of a language will run into the thousands. Cuneiform, thus, gradually developed into a combined system, where the same set of signs could be used to represent logograms and phonograms or syllabograms. In texts of our period, i.e. late third and early second millennium, logograms were used to write content words and the base (root) of a word, while phonograms were used to write bound morphemes and loan words. Language has two basic functions or metafunctions. One is to make sense of our experience, e.g. by listing things or professions that belong together (the experiental metafunction); the other is to act out social relationships, e.g. by asking questions, giving orders, making offers, expressing our attitudes, etc. (the interpersonal metafunction). Both types of functions are normally present in any stretch of language use. However, early cuneiform writing did not usually indicate the second type of function in the writing. This is why we cannot always tell whether someone named in a text is receiving or giving something, recording or accepting something. Thousand years on from the earliest attestations of cuneiform writing, when some of the texts of the ETCSL were written down, the so-called interpersonal metafunction of language was present in the writing system in the form of a more fixed word order, grammatical (bound) morphemes indicating subject, object, modality, aspect, etc., and function words, e.g. pronouns and determiners. More on the development of cuneiform writing and the script itself can be found on the Mesopotamia page at The British Museum web site. There is also a good description in Wikipedia. See also Further reading below. The cuneiform signIn principle, cuneiform signs of our period (ca. 2100 - 1650 BCE) are made up of a small set of imprints or wedges (cuneiform = wedge-shaped), e.g. Transliterating cuneiformIn our context, transliteration means representing cuneiform signs in the Roman alphabet, with the addition of a few non-Roman letters (š, ĝ/g̃ and ḫ), using hyphens and spaces to indicate sign boundaries (more about this in the document on hyphenation practices). A letter or a sequence of letters in lower case is called a (transliteration) value, and it may represent a word (logogram) or a grammatical morpheme (phonogram). Take the sign Determinatives are semantic classifiers written before, or sometimes after, another sign to show the meaning or semantic category of the following (preceding) sign. The most frequent determinative is There are a number of problems associated with reading cuneiform writing, e.g. interpreting the handwriting of the individual scribe or deciphering the signs on a tablet in poor condition, which we will not enter into here. The main problem, however, when transliterating cuneiform signs is their polysemous nature. Just like a word in English can have more than one meaning, e.g. 'might', so can a Sumerian sign. Another challenge for the aspiring Sumerologist is the fact that different signs are used to code the same phonetic value, that is homophony. To distinguish between homophonous signs subscript numbers have been introduced. gu ( Further readingBright W. and P. Daniels (eds). 1996. The world's writing systems. Oxford: Oxford University Press. Fischer, S.R. 2001. A history of writing. London: Reaktion Books. Glassner, J-J. 2003. The invention of cuneiform. Writing in Sumer. Translated and edited by Zainab Bahrani and Marc van de Mieroop. Baltimore & London: The John Hopkins University Press. Hayes, J.L. 2000. A manual of Sumerian grammar and texts. Second revised and expanded edition. Malibu: Undena Publications. Michalowski, P. 2004. Sumerian. In Roger D. Woodard (ed), The Cambridge encyclopedia of the world's ancient languages, Cambridge: Cambridge University Press, 19-59. Robinson, A. 1995. The story of writing. London: Thames & Hudson. Walker, C.B.F. 1987. Cuneiform. London: The British Museum Press. |
 |
© Copyright 2003, 2004, 2005, 2006 The ETCSL project, Faculty of Oriental Studies, University of Oxford |
 |
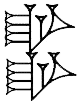
 ,
,  ,
, 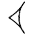 , combined at different angles. The signs range from the very simple to the highly intricate. The more intricate ones are sometimes made up of two or more simple signs either conjoined, or one sign may be written within another. Such signs are referred to as complex. Two examples are
, combined at different angles. The signs range from the very simple to the highly intricate. The more intricate ones are sometimes made up of two or more simple signs either conjoined, or one sign may be written within another. Such signs are referred to as complex. Two examples are 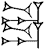 (DU&DU = "DU over DU"), one DU sign written on top of another DU sign and
(DU&DU = "DU over DU"), one DU sign written on top of another DU sign and 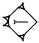 (HI×AŠ = "HI times AŠ"), the AŠ sign written inside the HI sign. There are also sequences of signs where the sequence is interpreted as constituting a unit. These are referred to as compound signs. To show that the two signs constitute a unit, they are, in modern transliteration, written together only separated by a period, as for example GAL.BUR2
(HI×AŠ = "HI times AŠ"), the AŠ sign written inside the HI sign. There are also sequences of signs where the sequence is interpreted as constituting a unit. These are referred to as compound signs. To show that the two signs constitute a unit, they are, in modern transliteration, written together only separated by a period, as for example GAL.BUR2 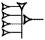
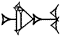 , which is transliterated ušumgal and means 'great dragon/snake'. Just like printed letters are very different from handwritten ones, the cuneiform signs shown above may differ quite a lot from signs imprinted on a tablet or carved in stone. To see how real signs imprinted on clay or carved into stone look, visit the
, which is transliterated ušumgal and means 'great dragon/snake'. Just like printed letters are very different from handwritten ones, the cuneiform signs shown above may differ quite a lot from signs imprinted on a tablet or carved in stone. To see how real signs imprinted on clay or carved into stone look, visit the  (NI), for example. It can be transliterated i3 with the meaning 'oil'. However, it can also be transliterated zal and mean 'to pass' as in 'to pass the time' (ud zal). This one-to-many relationship between sign and values is a real challenge for anyone transliterating Sumerian. It seems to have been so for the Mesopotamian scribe as well, and may be one of the reasons why determinatives are used so frequently.
(NI), for example. It can be transliterated i3 with the meaning 'oil'. However, it can also be transliterated zal and mean 'to pass' as in 'to pass the time' (ud zal). This one-to-many relationship between sign and values is a real challenge for anyone transliterating Sumerian. It seems to have been so for the Mesopotamian scribe as well, and may be one of the reasons why determinatives are used so frequently. (AN) written before a deity's name. Another is
(AN) written before a deity's name. Another is 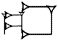 (URUDA) written before objects of copper. Determinatives are thought not to have been pronounced, and are therefore marked in a special way in transliteration. On the ETCSL web site, they are displayed in superscript or as entities, bounded by & and ; (semicolon), e.g. &urud;.
(URUDA) written before objects of copper. Determinatives are thought not to have been pronounced, and are therefore marked in a special way in transliteration. On the ETCSL web site, they are displayed in superscript or as entities, bounded by & and ; (semicolon), e.g. &urud;.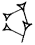 (UD) for instance can stand for 'sun', 'day', 'storm', 'white', and 'to shine'. In Sumerian, as in English, the context will decide which meaning is intended. However, the more meaning potential a word or sign has, the more difficult it is to assign the correct interpretation. When transliterating a Sumerian text, we also interpret it by assigning different values to the individual signs based on what we believe the most likely meaning is in a particular context. Sometimes the several values of a sign have related meanings, making it even more difficult to decide on a value even with an extended context. One such sign is DU
(UD) for instance can stand for 'sun', 'day', 'storm', 'white', and 'to shine'. In Sumerian, as in English, the context will decide which meaning is intended. However, the more meaning potential a word or sign has, the more difficult it is to assign the correct interpretation. When transliterating a Sumerian text, we also interpret it by assigning different values to the individual signs based on what we believe the most likely meaning is in a particular context. Sometimes the several values of a sign have related meanings, making it even more difficult to decide on a value even with an extended context. One such sign is DU 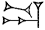 , which has the values du (a form of the verb 'to go'), de6 ('to bring/carry'), gub ('to stand'), and ĝen ('to go') among others.
, which has the values du (a form of the verb 'to go'), de6 ('to bring/carry'), gub ('to stand'), and ĝen ('to go') among others.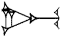 = GU), gu2 (
= GU), gu2 (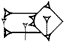 = GU2), and gu3 (
= GU2), and gu3 (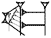 = KA) are good examples. An English parallel would be the word 'bust'. If you look this word up in a dictionary you will see that there are two entries, (often) distinguished by superscript numbers, although the words are pronounced the same. This is because they have different, unrelated meanings, just like gu = 'cord/net', gu2 = 'neck/bank', and gu3 = 'voice'. In the example with gu/2/3 the same phonetic value stems from different signs AND have different meanings. This is not always the case. Sometimes different transliterations (graphic values) have the same meaning whether they stem from the same sign or not. This is called heterography. The values ba, bad, be2 are cases in point. They can all mean 'to open'.
= KA) are good examples. An English parallel would be the word 'bust'. If you look this word up in a dictionary you will see that there are two entries, (often) distinguished by superscript numbers, although the words are pronounced the same. This is because they have different, unrelated meanings, just like gu = 'cord/net', gu2 = 'neck/bank', and gu3 = 'voice'. In the example with gu/2/3 the same phonetic value stems from different signs AND have different meanings. This is not always the case. Sometimes different transliterations (graphic values) have the same meaning whether they stem from the same sign or not. This is called heterography. The values ba, bad, be2 are cases in point. They can all mean 'to open'.