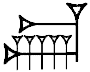
Values: ga3, gan2, gana2, iku, kan2
| ETCSLlemmatisation | | Sign name: GAN2 Values: ga3, gan2, gana2, iku, kan2 |
IntroductionAccording to Collins English Dictionary (1991), to lemmatise means "to group together the inflected forms of a word for analysis as a single item". Compared to many other languages, Sumerian has few inflected forms, but the aspectual and/or temporal distinction which is found in verbs seems to be one of inflection. In addition to inflected forms, Sumerian, as reflected in the ETCSL, contains variant forms of the same word. This stems from the fact that a word can be written using different logograms having the same sound value as well as by using phonograms only. To simplify the search for and analysis of Sumerian words, it is therefore useful to group forms together under one lemma or citation form. A more appropriate term for this "single item" may be lexeme, which would also include multiword units, e.g. di kud (verdict/judgement cut) = to judge. We will use the term lemmatisation for the process of grouping all forms of a word, including multiword units, under one lexeme (lemma/citation form). The definition of 'word' in Sumerian is not unproblematic. Crystal (A dictionary of linguistics and phonetics, 1991) begins his article on the word by saying that it is "a unit of expression which has universal recognition by native speakers, in both spoken and written language". Later he goes on to suggest, following Leonard Bloomfield, that a word is a 'minimum free form', and "the smallest unit which can constitute, by itself, a complete utterance" (ibid.). Clearly, none of these definitions are fully satisfactory working definitions when trying to decide whether a particular sign sequence should make up a word in Sumerian. Our approach has therefore necessarily been pragmatic. The document Hyphenation principles goes some way towards describing the many aspects involved in arguing for a word in Sumerian. Preparation for lemmatisationSince the main work of grouping inflected and variant forms together was to be done automatically using Steve Tinney's Sumerian lemmatiser1, it was important that the corpus was standardised and consistent, and that Tinney's program had access to all the words of the corpus. The work of standardising the corpus and of comparing and harmonising the words in the ETCSL with the electronic version of the Pennsylvania Sumerian Dictionary (ePSD) took more than a year to complete, but was crucial for the success of the automatic lemmatisation. The fact that proper nouns had been tagged as such from the early start of the project greatly helped to reduce the number of ambiguously tagged words (more about this below). It must also be mentioned that several texts of the corpus contain mainly phonographic writing. These texts were manually tagged, and were not included in the automatic lemmatisation process. Finally, to make it easier for the lemmatiser to pick out the individual words from the corpus files, every word form was extracted and made the value of an attribute. At the same time the corpus files were converted to a vertical format, so that we now have one word per line of text. A line of Sumerian is now spread across several lines, <l n="8" id="c134.C.8" corresp="t134.p3"> <w form="ugnim-e">ugnim-e</w> <w form="igi">igi</w> <w form="im-ma-an-sig10">im-ma-an-sig10</w> </l> as compared to the earlier format, <l n="8" id="c134.C.8" corresp="t134.p3">ugnim-e igi im-ma-an-sig10</l>. The output from the lemmatiserThe main task of the lemmatiser is to analyse every word form and assign to it a part of speech (N, V, etc.), an ePSD citation form (ugnim, igi, igi sig), a guide word (English translation or gloss, e.g 'army', 'to see'), and a morphological analysis of the word form into its parts, i.e. base and affixes/clitics (ugnim,e, igi, Vmma.n:sig10). <l n="8" id="c134.C.8" corresp="t134.p3"> <w parses="N\ugnim\army\ugnim,e" form="ugnim-e">ugnim-e</w> <w parses="N\igi\#cvn\igi" form="igi">igi</w> <w parses="CV\igi_sig\to_see\Vmma.n:sig10" form="im-ma-an-sig10">im-ma-an-sig10</w> </l> Having the corpus files enriched with this kind of information hugely increases their usefulness. One can now not only search for word forms in the corpus, but also for parts of speech, English translations or glosses, and most importantly of all, lexemes. Despite its basic usefulness, the output from the ePSD lemmatiser also created a few problems. Since it is geared towards recognising lexemes, it did not always give us all the information we wanted. As can be seen from the above output, it did not give us a translation or a gloss for the word igi since it is part of the lexeme igi sig (eye place) = 'to see'. Furthermore, the lexeme igi sig, which was correctly recognised as a multiword unit, is an ePSD citation form, whereas we would like, at this stage of the corpus enhancement process, to separate out the various parts of multiword units, and have igi as one lexeme and sig10 as another, as shown next.2 <l n="8" id="c134.C.8" corresp="t134.p3"> <w form="ugnim-e" lemma="ugnim" pos="N" label="troops" bound="L,e">ugnim-e</w> <w form="igi" lemma="igi" pos="N" label="eye">igi</w> <w form="im-ma-an-sig10" lemma="sig10" pos="V" label="to place" bound="Vmma.n:L">im-ma-an-sig10</w> </l> This slight difference in objective coupled with the fact that we did not always agree with the output from the lemmatiser led to the decision that we should proofread the output before we merged all that information with the corpus files. This, it must be said, was a major undertaking. However, it did not only improve, in our view, the output from the lemmatiser, but it also unearthed further inconsistencies in the corpus data, which we hence were able to correct. Lexemes and English glossesThe choice of lexeme selected to represent a set of forms is not always self-evident. However, in most cases we have chosen the form that is most frequently attested in the corpus. In fact, this has been a guiding principle from the very start, namely to have as lexemes only forms found in the corpus. Note that our lexemes do not correspond directly to the headwords of the ePSD, which are made up of citation form+guide word. Rather, our lexemes correspond to one of the transliteration values for that headword. The overlap between ETCSL and ePSD is such that there in most cases is a one-to-one correspondence. We have therefore felt it to be safe to link our lexemes to a search for that transliteration value in the ePSD. The choice of English gloss or translation for a particular lexeme is more difficult to decide, and hence to explain. Since we are constrained by space in a way a dictionary is not, we urge people to go to the ePSD to get the full range of meanings a lexeme can have, and also to compare with the translation of that lexeme in context. Still, we hope that our glosses (labels) will be useful in interpreting the Sumerian data. Some figuresAt the time of lemmatisation, the ETCSL contained 167,952 items tagged as word forms. Of these, 129,012 were given a parse (analysis) by the lemmatiser. The remaining 38,940 were made up of non-recognisable signs or sign sequences, marked as X or &X; in the corpus; recognisable signs for which we have not been able to assign a value, set out in the text by having the sign name in capital letters; and words already lemmatised, e.g. proper nouns, cardinal numbers and all the words of the texts containing phonographic writing. 4,631 forms were not recognised by the lemmatiser, and had to be lemmatised manually by the ETCSL project team. These included all the Emesal words in the corpus, approx. 2,100 at the time. 2,759 items were tentatively recognised by the lemmatiser, i.e. a lexeme was suggested, but no English gloss was supplied. Some of these were wrongly lemmatised, i.e. subsumed under the wrong lexeme and/or given an incorrect part-of-speech label. Most of them were dealt with when proofreading the lemmatiser output, while some were done manually later in the process. The biggest challenge in terms of numbers was the 17,895 word forms analysed by the automatic lemmatiser as ambiguous (indicated by the vertical bar), which we have had to disambiguate. The form unu2 is a case in point. <w parses="N\unu\adornment\unu2|N\unu\dwelling\unu2|N\unu\girl\unu2|N\unu\meal\unu2" form="unu2">unu2</w> DisambiguationDisambiguating the output from the lemmatiser has been a slow process. Despite the fact that we have been able to resolve many of the ambiguities automatically by taking context into consideration, e.g. lemmatising si as 'horn' and not 'to fill' when preceding sa2, in many cases there was no way of getting around looking up every individual instance and compare with the translation. The work of manual disambiguation is at the time of writing (March 2005) not completely finished. We are still left with a small set of words, which are highly frequent and ambiguous in many contexts, e.g. a = 'water' or 'soothing expression' and mu = 'name' or 'year'. As long as the correct analysis is among the ones given by the lemmatiser, ambiguities are not crucial in interpreting the corpus data. More serious are the cases where the lemmatiser has suggested only one analysis, but a wrong one, because there is no way we can find all these instances except by proofreading the whole corpus. As far as we have been able to ascertain, this only occurs very infrequently, and we hope we have been able to correct most of these. Nouns beginning with nam- and other potential verbal prefixes have caused the lemmatiser some problems. Also word forms like mu-zu (name-your|ventive-know) = 'name' or 'to know', which the lemmatiser consistently lemmatised as <w parses="V\zu\to know\mu:zu" form="mu-zu">mu-zu</w>, had to be checked manually. AcknowledgementsWe are grateful to Steve Tinney for running his lemmatiser on the ETCSL data. This made the whole task of lemmatising the corpus seem manageable. Without the help of Naoko Ohgama, a DPhil student here in the Oriental Institute, we would never have achieved our goal on time. She did much of the manual tagging and disambiguation, and helped in recognising sequences of words to be automatically disambiguated. Jarle Ebeling lent a hand in manual tagging and disambiguation, and did most of the electronic post-processing of the data. Jon Taylor and Gabór Zólyomi were always at hand and gave useful advice on particular problematic points of lemmatisation. Most of the work was done by Graham Cunningham. We would also thank our guardian me Jeremy Black, who set the whole process in motion many years ago. |
1. The lemmatiser is really a suite of programs that are run on the input data, i.e. the ETCSL in this case. For the sake of simplicity, and the fact that we only have access to the start and end product of the process, it will be regarded as one piece of (sophisticated) software here, and termed "the lemmatiser". There is presently no description of the lemmatiser on the web, but interested parties can contact Steve Tinney directly.
2. For reasons we are not going into here, the names of the various attributes as they appear in the corpus files are lemma (= lexeme), pos (= part of speech), label (= translation/gloss), and bound (= morphological segmentation).
 |
© Copyright 2003, 2004, 2005, 2006 The ETCSL project, Faculty of Oriental Studies, University of Oxford |
 |